


华裔科学家成功解码脑电波,AI直接从大脑中合成语音(组图)
大脑活动能够解码成语音了。
说话似乎是一项毫不费力的活动,但它其实是人类最复杂的动作之一。说话需要精确、动态地协调声道发音器官结构中的肌肉——嘴唇、舌头、喉部和下颌。当由于中风、肌萎缩侧索硬化症或其他神经系统疾病而导致言语中断时,丧失说话能力可能是毁灭性的。
来自加州大学旧金山分校的科学家创造了更接近能够恢复说话功能的脑机接口(brain–computer interface,BCI)。
脑机接口旨在帮助瘫痪患者直接从大脑中“读取”他们的意图,并利用这些信息控制外部设备或移动瘫痪的肢体,这项技术目前能够使瘫痪的人每分钟最多能打出8个单词,而加州大学旧金山分享的研究人员开发了一种方法,使用深度学习方法直接从大脑信号中产生口语句子,达到150个单词,接近正常人水平!
这项研究发表在最新一期《自然》杂志上,作者为Anumanchipalli以及华裔科学家Edward Chang等人。

01.每分钟能够生成150单词,接近正常人类水平
加州大学旧金山分校的研究人员与5名志愿者合作,志愿者们接受了一项被称为“颅内监测”的实验,其中电极被用于监测大脑活动,作为癫痫治疗的一部分。
许多癫痫患者的药物治疗效果并不好,他们选择接受脑部手术。在术前,医生必须首先找到病人大脑中癫痫发作的“热点”,这一过程是通过放置在大脑内部或表面的电极来完成的,并监测明显的电信号高峰。
精确定位“热点”的位置可能需要数周时间。在此期间,患者通过植入大脑区域或其附近的电极来度日,这些区域涉及运动和听觉信号。这些患者一般会同意利用这些植入物进行额外的实验。

ECoG电极阵列由记录大脑活动的颅内电极组成
此次招募的五名志愿者同意测试虚拟语音发生器。每个患者都植入了一两个电极阵列:图章大小的、包含几百个微电极的小垫,放置在大脑表面。
实验要求参与者背诵几百个句子,电极会记录运动皮层中神经元的放电模式。研究人员将这些模式与患者在自然说话时嘴唇,舌头,喉部和下颌的微小运动联系起来。然后将这些动作翻译成口语化的句子。
参与的志愿者大脑中的电极阵列位置
实验要求母语为英语的人听这些句子,以测试虚拟语音的流畅性。研究发现,大约70%的虚拟系统生成的内容是可理解的。
最终,这套新系统每分钟能够生成150单词,接近自然讲话的语速水平。而以前基于植入物的通信系统每分钟可以生成大约8个单词。
02.技术细节:两阶段解码方法
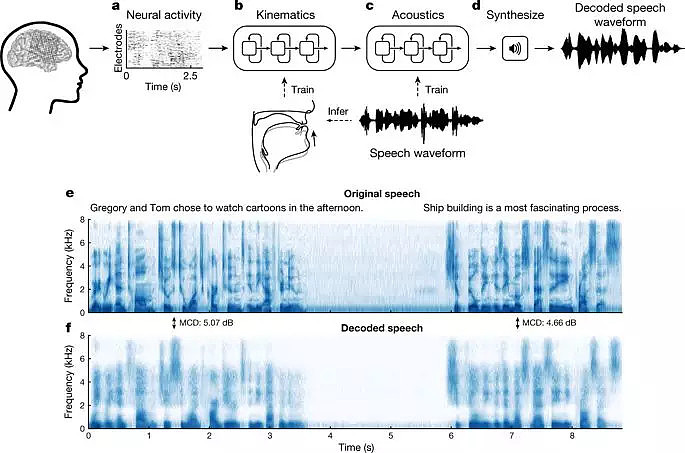
在这项工作中,研究人员使用了一种叫做高密度皮层脑电图的技术来跟踪志愿者说话时大脑中控制言语和发音器官运动的区域的活动,志愿者们被要求说了几百句话。
为了重建话语,Anumanchipalli等人不是将大脑信号直接转换为音频信号,而是使用一种两级解码的方法。他们首先将神经信号转换为声道发音器官运动的表示,然后将解码的运动转换为口语句子,如图1所示。两次转换都使用了递归神经网络——一种人工神经网络,在处理和转换具有复杂时间结构的数据时特别有效。
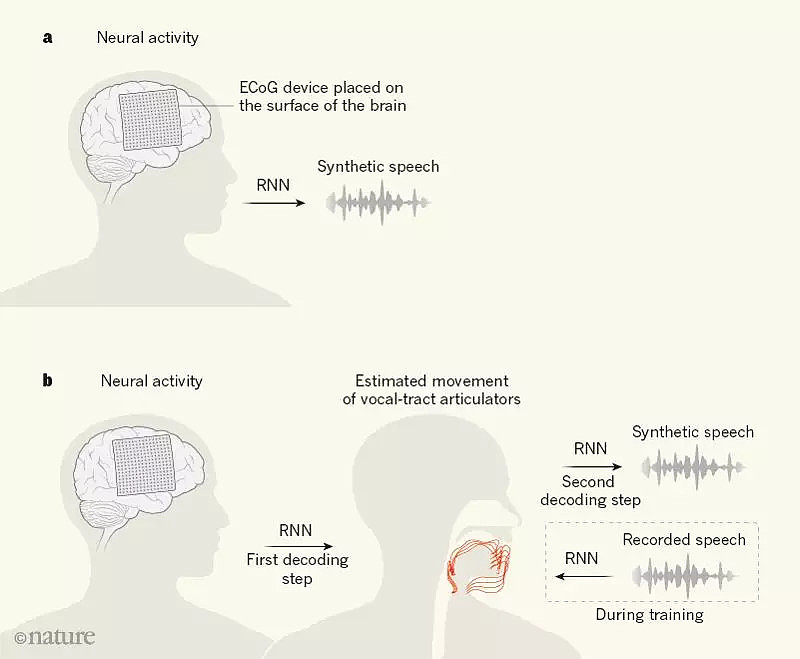
图1:语音合成的脑机接口
在上图A中,以前的语音合成研究采用的方法是使用脑电图(ECoG)设备监测大脑语音相关区域的神经信号,并尝试将这些信号直接解码合成语音,使用一种称为递归神经网络(RNN)的人工神经网络;
上图B中,Anumanchipalli等人开发了一种不同的方法,RNN被用于两阶段解码。其中一个解码步骤是将神经信号转换成声道发声器官(红色)的预估运动,涉及到语音生成的解剖结构(嘴唇、舌头、喉部和下颌)。为了在第一个解码步骤中进行训练,作者需要每个人的声道运动与他们的神经活动关联起来的数据。
因为无法直接测量每个人的声道运动,Anumanchipalli等人构建了一个RNN来预估这些运动,其训练数据是之前收集的大量声道运动数据和语音录音。
这个RNN产生的声道运动估计足以训练第一个解码器。第二个解码步骤将这些估计的动作转换成合成语音。Anumanchipalli和他的同事的两步解码方法产生的口语句子的失真率明显低于直接解码方法获得的句子。
与直接解码声学特征相比,作者采用的两阶段解码方法能明显减小声音失真。如果可以获得跨多种语音条件的海量数据集,那么直接合成可能会接近或优于两阶段解码的方法。
然而,考虑到现实中数据集的匮乏,解码的中间阶段会将声道发音器官正常运动功能的信息带入模型,并限制必须评估的神经网络模型的可能参数。这种方法似乎使神经网络能够实现更高的性能。最终,反映正常运动功能的“仿生”方法可能在复制自然语言典型的快速、高精度通信方面发挥关键作用。
03.不能说话的个体也能实现语音合成
在脑机接口(BCI)研究中,包括新兴的语音脑机接口领域,开发和采用允许跨研究进行有意义的比较的稳健度量是一项挑战。例如,重构原始语音的错误等度量可能与脑机接口的功能性能(即听者是否能听懂合成的语音)几乎没有对应关系。
为了解决这个问题,Anumanchipalli等人从语音工程领域出发,开发了易于复制的人类听众语音可懂度测量方法。他们在众包市场Amazon Mechanical Turk上招募用户,让志愿者识别合成语音中的单词或句子。
与重构错误或以前使用的自动可懂度测量方法不同,这种方法直接测量语音对人类听众的可懂度,而不需要与原始话语进行比较。
Anumanchipalli和他的同事的研究结果为语音合成脑机接口的概念提供了令人信服证据,无论是在音频重建的准确性方面,还是在听者对产生的单词和句子进行分类的能力方面。
然而,在通往临床可行的语音脑机接口的道路上仍有许多挑战。
重构语音的可理解性仍远低于自然语音,脑机接口能否通过收集更大的数据集并继续开发底层的计算方法来进一步改进还有待观察。使用记录局部脑活动的神经接口可能比使用皮层脑电图记录的更为有效。例如,在脑机接口研究的其他领域,皮质内微电极阵列通常比皮质脑电图具有更高的性能。
目前所有语音解码方法的另一个限制是需要使用语音来训练解码器。因此,基于这些方法的脑机接口不能直接应用于无法说话的人。
但是Anumanchipalli和他的同事们发现,当志愿者在不发声的情况下模仿语音时,语音合成仍然是可行的,尽管语音解码的准确率要低得多。无法产生语音相关动作的个体是否能够使用语音合成脑机接口是未来研究的一个问题。
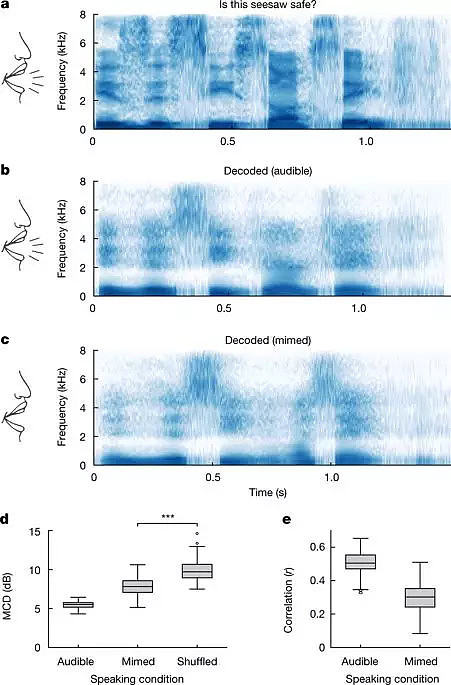
基于神经解码的无声模仿语音合成
值得注意的是,在首次对脑机接口进行概念验证研究以控制健康动物的手臂和手的运动之后,人们对这种脑机接口在瘫痪患者身上的适用性提出了类似的问题。随后的临床试验令人信服地证明,使用脑机接口,人类可以快速交流、控制机械臂、恢复瘫痪肢体的感觉和运动等。
最后,这些令人信服的概念验证证明了不能说话的个体也能实现语音合成,结合脑机接口在上肢瘫痪患者中的快速进展,研究人员认为应该大力考虑涉及言语障碍患者的临床研究。
随着持续的进步,希望更多有语言障碍的人能够重新获得自由表达思想的能力,并重新与周围的世界联系起来。
华裔科学家解码,马斯克脑机接口公司也会有新动作
Nature这篇文章的作者之一是加州大学旧金山分校神经外科教授Edward Chang博士。

Edward Chang
Edward Chang博士的研究重点是言语、运动和人类情感的大脑机制,同时他也是加州大学旧金山分校和加州大学伯克利分校的合作单位——神经工程与假肢中心的联合负责人。该中心汇集了工程、神经病学和神经外科方面的专家,以开发最先进的生物医学技术,用以恢复神经系统残疾患者的功能,如瘫痪和言语障碍。
Edward Chang博士表示,这次在Nature上的研究,“我们通过解码大脑活动提升语音的清晰度,模拟的语音比从大脑中提取声音表示的合成语音更准确、更自然。”
人类将大脑与计算机相连的努力越来越多。
上个月,美国一组科学家在biorxiv.org上发表一篇论文,称找到了快速将电线植入大鼠大脑的方法,论文中描述这个过程是“向人类大脑直接插入计算机潜在系统迈出的重要一步”。
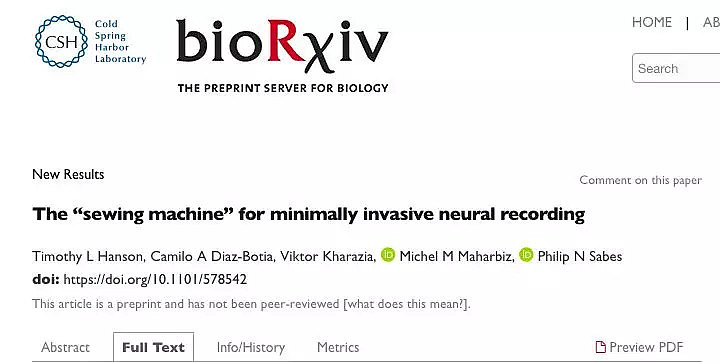
研究人员将他们的系统称为“缝纫机”(sewing machine),科学家在实验室中移除一块老鼠的头骨并插入一根针头,将柔性电极送入老鼠的脑组织。
彭博新闻报道,这组科学家与马斯克的脑机接口公司Neuralink有各种松散关联。
Neuralink于2016年注册为加州的一家医学研究公司,该公司聘请了来自不同大学的几位知名神经科学家,并与加州大学戴维斯分校的实验室签约,对灵长类动物进行研究。
本周三,当Twitter用户询问Neurink的进展时,马斯克说,“可能会在几个月内宣布一些值得注意的事情。”
马斯克认为,脑机接口技术能在2021年之前治疗严重的脑损伤。此外,科学可以通过脑机接口扩大人类的能力。他举了一个例子:人们可以通过心灵感应来传达复杂的概念,“你不需要用语言表达”。
人类是否有一天会与机器合并?马斯克认为,人类已经在某种程度上做到了这一点,因为智能手机等近乎无所不在的技术,因此脑机接口这项工作应该继续下去。
这可能会导致科幻未来,因为人们可以在脑海中下载外语,你觉得呢?







 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


